Реляционные БД:
- что такое РБД
- разница между MyISAM и InnoDB
- что такое нормализация и денормализация? зачем нужны нормализация и денормализация?
- применение нормальных форм
- внешние ключи и зачем они нужны
- зачем нужны индексы?
- виды индексов
- как работают индексы?
- Что такое запросы SQL
- применение JOIN: INNER, CROSS, LEFT, RIGHT
- транзакции
- триггеры
База данных она и в африке база данных. Хотя несомненно кто-то ее представляет в виде папочек в архиве, но последние лет 20 это понятие все же относится именно к компьютерной базе данных т.е. таблицам с данными, структурированными и отобранными определенным образом. Реляционная БД это подвид БД где данные из различных таблиц связаны между собой по полям-ключам. Помнится мне я как раз лекцию в институте по этому читал. Вспоминать интересно, а вот описывать нет:)

Нормализация БД и ее антипод денормализация это приведение структуры данных к такому типу чтобы одни и те же данные хранились только один раз. Т.е. к примеру адрес проживания нет смысла хранить в каждой таблице, выгодней использовать таблицу адресов и связывать их с записями. Вдруг у нас в одной квартире живет 100500 людей, тогда мы экономим кучу ресурсов. 🙂
БД бывают InnoDB и MyISAM. Первый тип это БД с поддержкой транзакций и при записи данных блокируется не вся таблица, а одна строка. У второго типа ситуация обратная при записи блокируется вся таблица и это не очень хорошо. КАк всегда использование обоих типов имеет плюсы и минусы и подбирается в зависимости от требований к системе.
Как уже было сказано выше данные в РБД связаны между собой с использованием определенных полей ключей. Чаще всего это банальное поле ID содержащее униклаьное значение, например порядковый номер записи. В таком понимании это первичный ключ таблицы. Понятно их может ыть в таблице и не один. Я в своей жизни встречал таблицу из 64 полей ключей. Других данных там просто не было. Однако можно было выдернуть из БД всю необходимую информацию составив более чем трехэтажный запрос. Внешний ключ в этой терминологии как раз поле идентификатор ссылающееся на другую таблицу.

В большинстве случаев используются так называемые индексы. Нужны они для оптимизации работы. К примеру у нас есть таблица содержащая 100500 записей. Для того чтобы не тратить ресурсы на перебор всех записей в поисках искомой создается индекс и поиск ведется уже в нем. Например с использованием дерева. Представим себе нашут таблицу имеющую цифробуквенное индексное поле. В таком слуячае индекс по нему будет содержать дерево и при поиске будет сначала выбрана ветка для первого знака, из нее ветка для второго знака и так далее пока мы не попадем на искомую запись. Индексы опять же бывают разные, как и методики работы СУБД с ними. В Oracle иногда это позволяло творить необычные вещи: я как то оптимизировал запрос который выполнялся по индексу несколько часов. С использованием хинтов меняющих логику обработки индекса, запрос выполнялся менее чем за минуту.
Запросы SQL — формализованный язык для взаимодействия с хранимыми данными. По сути обычное «дай мне то или удали вот это». Стандарт SQL подразумевает что общий синтаксис одинаков для всех СУБД, но как всегда у каждого свои заморочки.
В базовом варианте он без проблем позволяет осуществлять следующие операции:
- создание в базе данных новой таблицы;
- добавление в таблицу новых записей;
- изменение записей;
- удаление записей;
- выборка записей из одной или нескольких таблиц (в соответствии с заданным условием);
- изменение структур таблиц.
Для этого используются вот эти операторы:
-
- CREATE создает объект БД (саму базу, таблицу, представление, пользователя и т. д.)
- ALTER изменяет объект
- DROP удаляет объект
- операторы манипуляции данными (Data Manipulation Language, DML)
Я не буду их подробно рассматривать ибо это основы SQL расписанные в любой литературе. Я их пока еще помню 🙂
Лично для меня всегда была тягомотина с двумя операторами JOIN и UNION. На уровне абстракций первый необходим для логического соединения данных из различных таблиц в одно большое представление (например содержащее ФИО, адреса и должности из трех таблиц), а вот второй чаще всего используется для соединения однотипных данных из таблиц, например продажи по годам, в одну пригодную для дальнейшего анализа.
Логика их сложна, но дьявол живет в деталях. И с наскоку набросать select из десятка таблиц с логикой и не сматериться бывает сложно. Хотя когда я работал DBA над ORACLE это было плевое дело. Собственно за эти годы я только потерял виртузное владение предметом, а если вспомнить могу еще ого-го что делать.
Ну и у нас осталось совсем немного. Транзакция это грубо говоря пакет инструкций и изменений который выполняется над данными. Чаще всего обратимо и подконтрольно. В случае ошибки ли повреждения даных используя транзакции данные можно восстанавливать или откатывать к первоначальному состоянию.
Триггер как и следует из самого термина, это некий переключатель. При определенных условиях он производит определенные действия. К примеру появилась новая запись в таблице, соответствующий триггер отработал и внес изменения (создал) в записи других таблиц. На википедии достаточно хорошо все описано
Ну и напоследок попробуем сделать запрос. Имеется БД
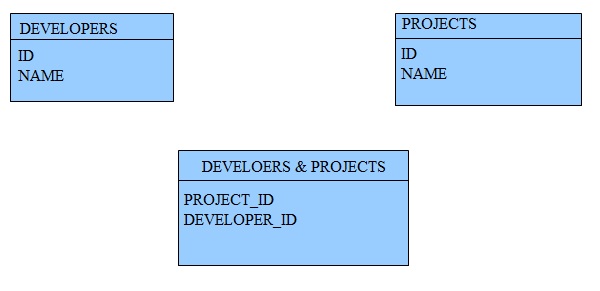
Необходимо выбрать разработчика с проекта №3.
И вот тут, подумав, я решил посвятить этому вопросу отдельный пост. Ибо меня на маке не стоит MySQL| Это нужно поправить
Комментариев нет